According to the global advisory firm Gartner, unstructured data makes up to 80% of enterprise information. Information such as documents, reports, emails, logs, support tickets, and much more are siloed in unactionable files and stored much in the same way that data has been stored since the invention of the filing cabinet. There have been steps toward modernization—keyword search was a boon in the 90s, and the advent of cloud computing was a huge thrust to managing data at scale with efficiency and convenience—but again, this data is stored in files much the same way as it was 100 years ago. Progress pushed big data to the brink, stored it far away, and made it easily shareable: a resounding success, but not a stopping point.
Large language models (LLMs) were supercharged with the 2020 breakthrough of Retrieval Augmented Generation (RAG), and their combined power has been the gold standard in enterprise AI use ever since. Unfortunately, this combo has critical shortcomings: RAG and LLMs retrieve text, not truth. They don’t provide reasoning, they provide similarity. And most concerningly, they hallucinate and compound their fallibility as document sets scale.
LLMs and RAG have improved exponentially, but there is a fundamental flaw in the algorithm that inhibits both scaling and reasoning. In the same way we have extracted the limits of performance out of the internal combustion engine, the RAG/LLM combo is handicapped and confined to performance constraints inherent to its architecture. What is needed is a new way to harness the capabilities of that engine—a superior transmission and accoutrements that elegantly magnify neural bandwidth.
A paradigm shift in data analysis, interaction, and storage.
Cassandra was built as the solution to the problems of modern data management: an Information Relationship Management (IRM) system that understands your world, demonstrates trust through rigorous audit pipelines, and scales with your needs. There are two operative words in that title that merit exploration: “information” and “relationship.” Information in a vacuum is useless. It’s through nuanced connection with other key insights that meaning is cultivated, and the more connections you can highlight and preserve, the greater the value of any individual piece of information.
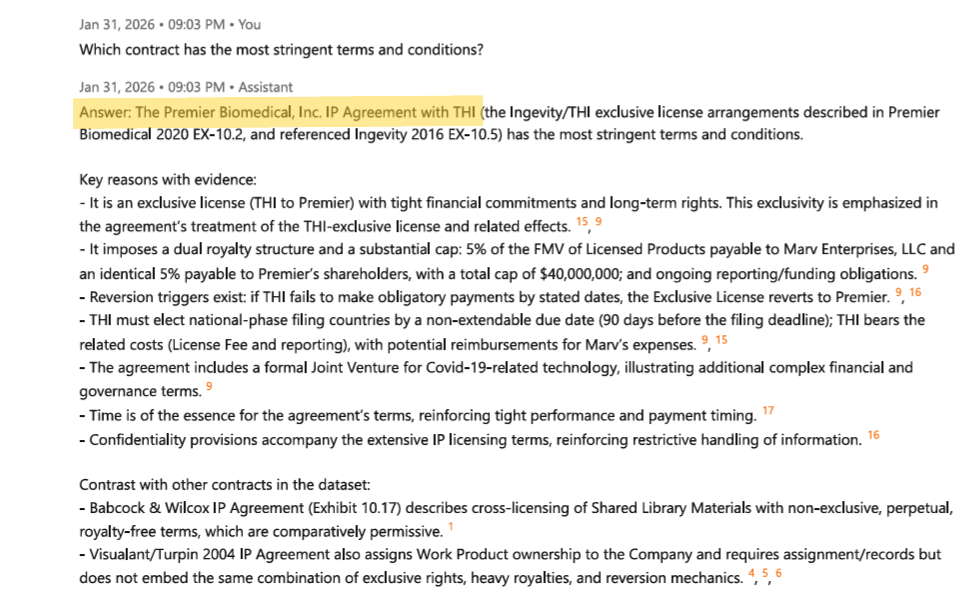
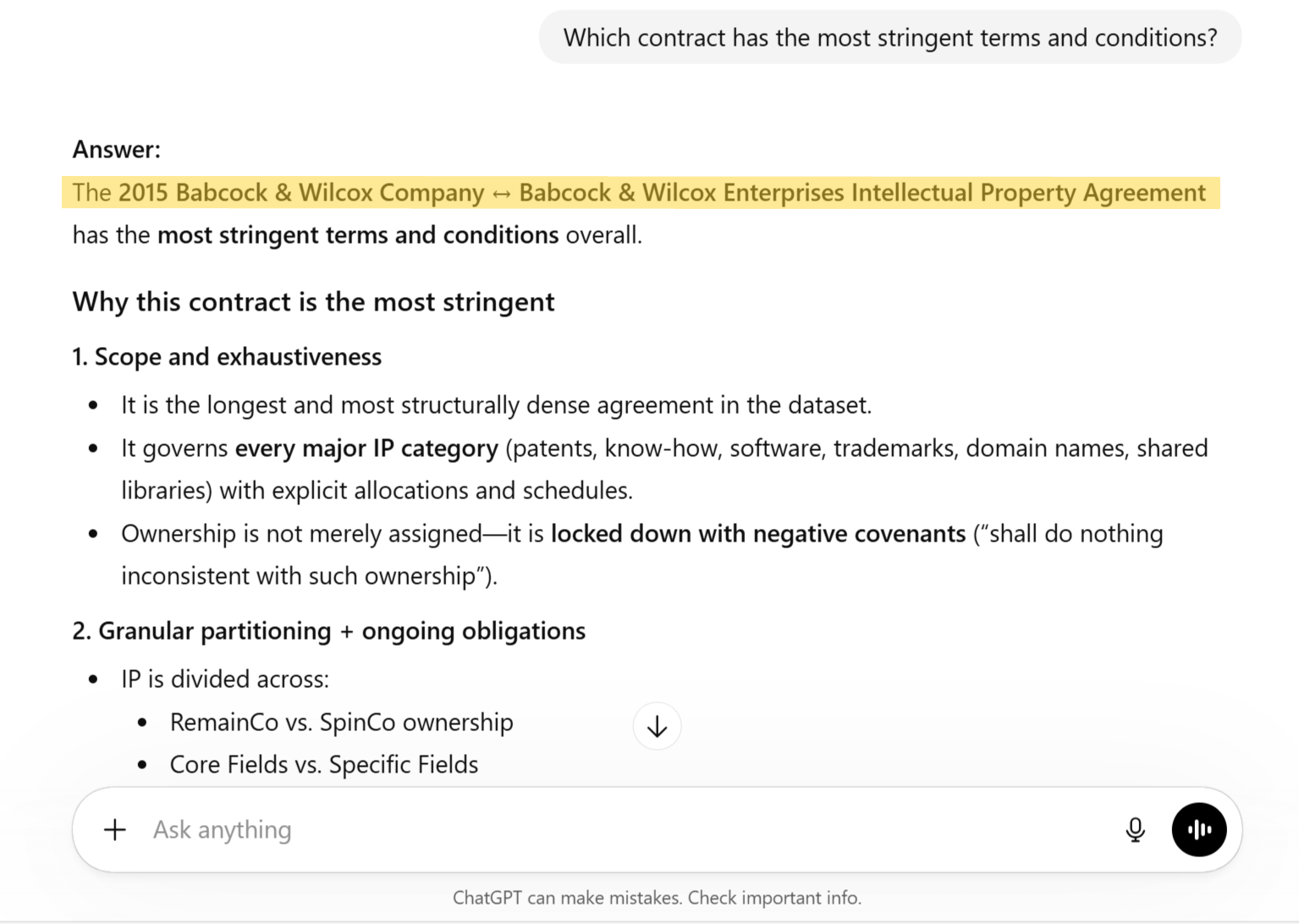
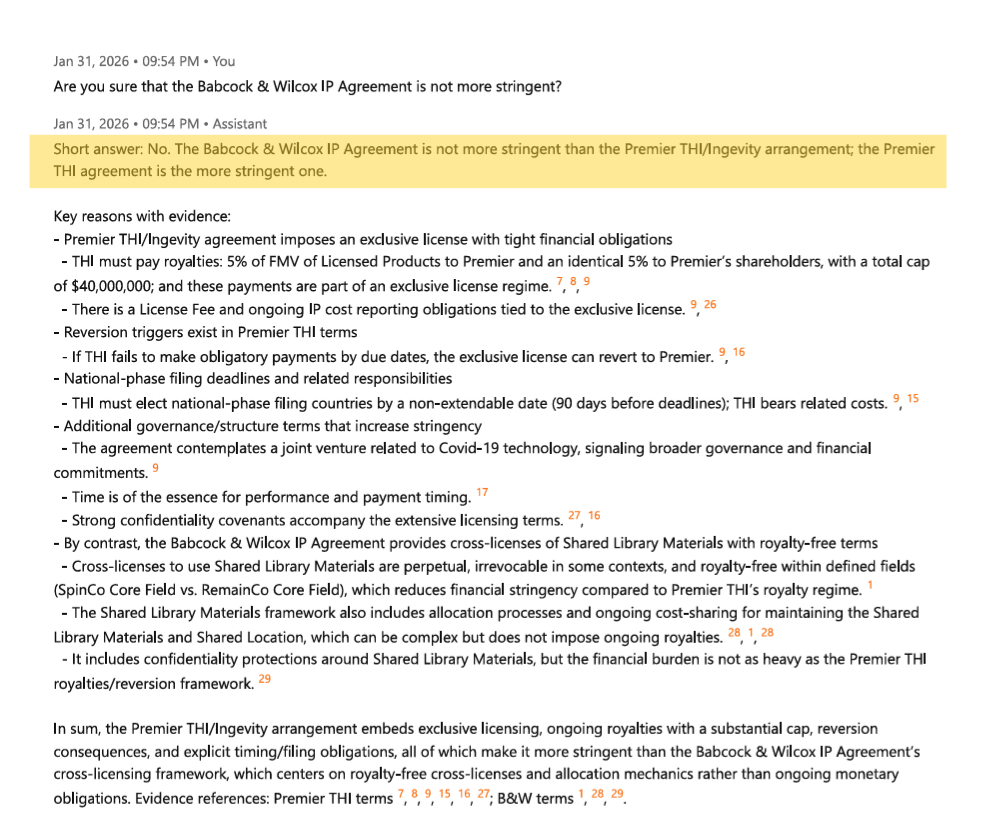
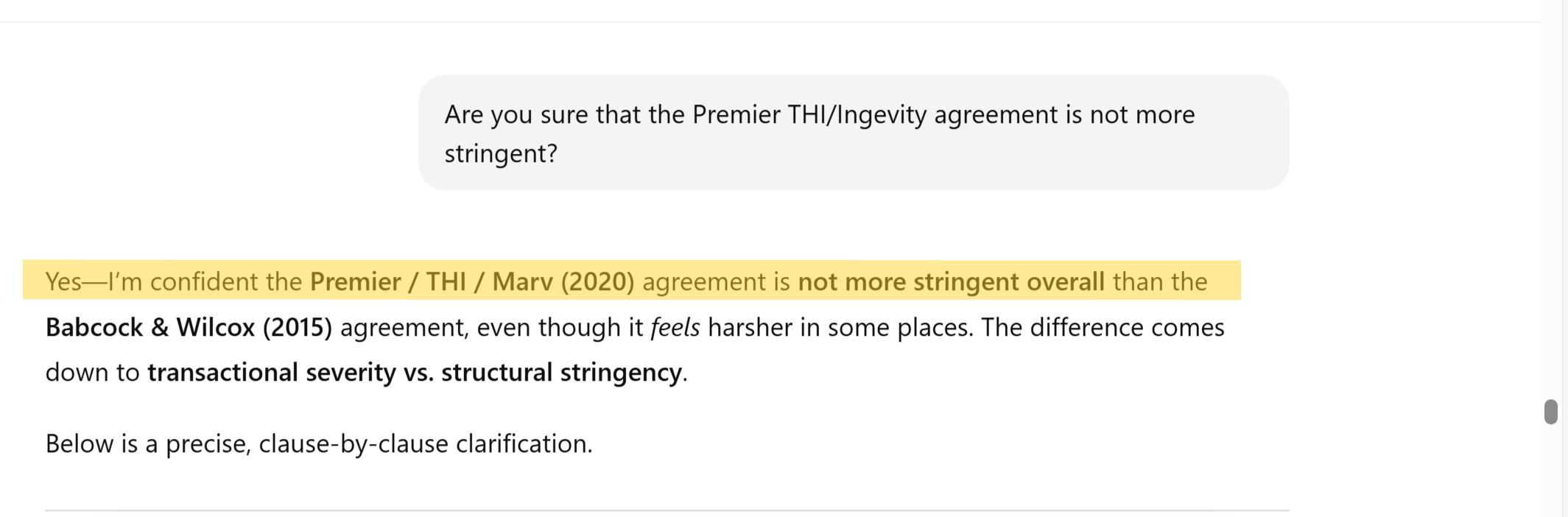
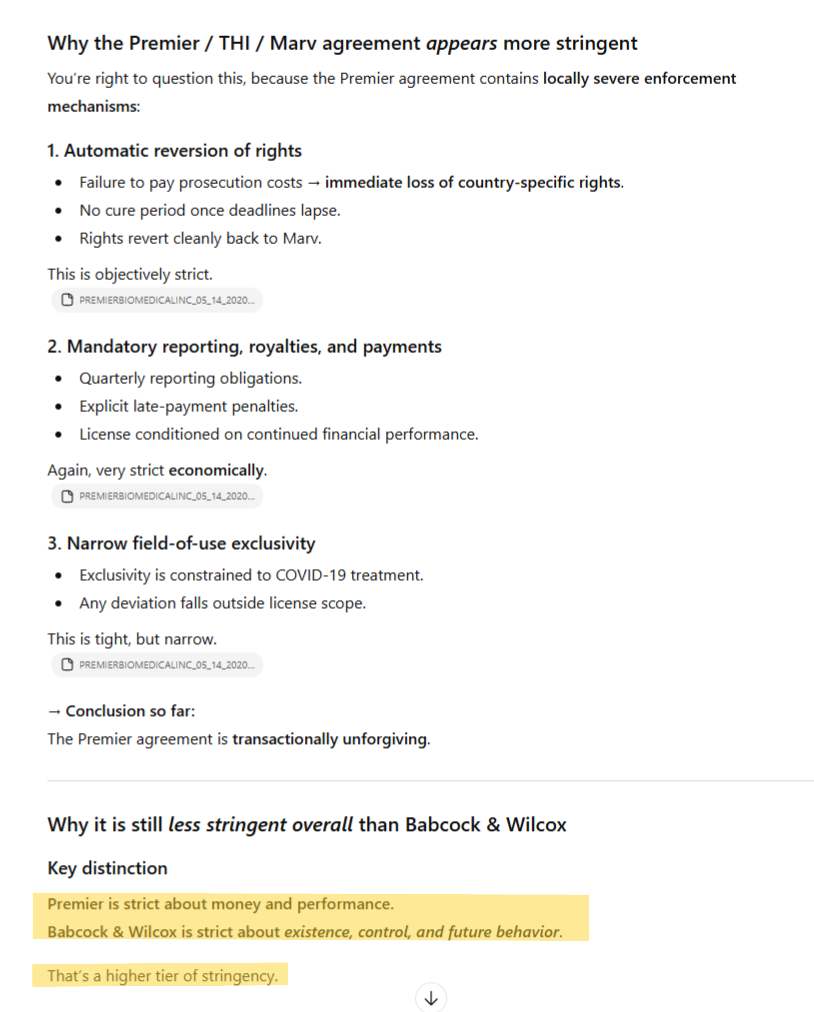
In the information that follows, we explore the depth and breadth of reasoning ability that Cassandra affords the user. Specifically, we compare the richness of information possible using Cassandra relative to the typical RAG/LLM pipeline outputs used in status quo enterprise systems.